
 MacBook
MacBook iPad
iPad Apple Watch
Apple Watch Airpods
Airpods iMac
iMac Studio Display
Studio Display iphone
iphone
 Gaming Laptop
Gaming Laptop

 Gaming Desktop
Gaming Desktop
 DDR5 Desktop
DDR5 Desktop DDR5 Laptop
DDR5 Laptop DDR5 Server
DDR5 Server DDR4 Desktop
DDR4 Desktop DDR4 Laptop
DDR4 Laptop DDR4 Server
DDR4 Server DDR3 Desktop
DDR3 Desktop DDR3 Laptop
DDR3 Laptop DDR3 Server
DDR3 Server
 Intel Socket
Intel Socket Intel Z890
Intel Z890 Intel B860
Intel B860 Intel B760
Intel B760 Intel H770
Intel H770 Intel B660
Intel B660 Intel H670
Intel H670 Intel H610
Intel H610 Intel Z690
Intel Z690 Intel H510
Intel H510 Intel Z590
Intel Z590 Intel B560
Intel B560 Intel H470
Intel H470 Intel Z490
Intel Z490 Intel H410
Intel H410 Intel B460
Intel B460 Intel H310
Intel H310 Intel B360
Intel B360 Intel B365
Intel B365 Intel X299
Intel X299 Intel Z390
Intel Z390 Intel Z370
Intel Z370 Intel H370
Intel H370 Intel Z270 H270
Intel Z270 H270 Intel B250
Intel B250 Intel Z170 H170
Intel Z170 H170 Intel H110
Intel H110 Intel H81
Intel H81 Intel B85
Intel B85 Intel H61
Intel H61 Intel B150
Intel B150 AMD Socket
AMD Socket AMD B850
AMD B850 AMD B840
AMD B840 AMD TRX50
AMD TRX50 AMD A620
AMD A620 AMD X870
AMD X870 AMD B650
AMD B650 AMD A520
AMD A520 AMD TRX40
AMD TRX40 AMD B550
AMD B550 AMD X570
AMD X570 AMD X470
AMD X470 AMD B450
AMD B450 AMD X370
AMD X370 AMD A320
AMD A320 AMD B350
AMD B350 AMD X399
AMD X399 AMD A88
AMD A88 AMD A68 A78
AMD A68 A78
 Cpu Air Coolers
Cpu Air Coolers CPU Liquid Coolers
CPU Liquid Coolers Fans
Fans
 AMD CPUs Desktop
AMD CPUs Desktop AMD Server CPU
AMD Server CPU Intel Server CPU
Intel Server CPU Samsung CPUs
Samsung CPUs Other special CPUs
Other special CPUs

 Solid State Drives
Solid State Drives NVMe PCIe M.2
NVMe PCIe M.2 SATA 2.5inch
SATA 2.5inch Hard Disk Drive
Hard Disk Drive Server Hard Drives
Server Hard Drives NAS hard drive
NAS hard drive Monitoring hard drive
Monitoring hard drive Portable Solid State Drives
Portable Solid State Drives Memory Cards
Memory Cards USB Flash Drives
USB Flash Drives
 Nvidia GPU
Nvidia GPU RTX 50 series
RTX 50 series RTX 30 series
RTX 30 series GTX 16 series
GTX 16 series GTX 10 series
GTX 10 series RX 9000 series
RX 9000 series RX 7000 series
RX 7000 series RX 6000 series
RX 6000 series RX 5000 series
RX 5000 series RX 500 series
RX 500 series RTX 20 series
RTX 20 series
 Rack server
Rack server Blade server
Blade server Tower server
Tower server Storage Server Solutions
Storage Server Solutions Network switch
Network switch
 Workstation
Workstation Mobile Workstation
Mobile Workstation
 Server motherboard
Server motherboard Workstation Motherboard
Workstation Motherboard
PSP3000索尼原装街机掌机-150x150.jpg) SONY Gaming Console
SONY Gaming Console ASUS Gaming Console
ASUS Gaming ConsoleLegion-Go-游戏掌机手持设备-150x150.jpg) Lenovo Gaming Console
Lenovo Gaming Console One XPlayer
One XPlayer日版-Xbox-Series-X-XSX次世代-150x150.jpg) Microsoft Gaming Console
Microsoft Gaming Console XBOX Gaming Console
XBOX Gaming ConsoleMSI-Claw-A1M-050US-游戏掌机-150x150.jpg) MSI Gaming Console
MSI Gaming Console Motherboard
Motherboard GTX TITAN
GTX TITAN Computer Cases
Computer Cases
The Accelerated Computing Platform for
Next-Generation Workloads
Learn about the next massive leap in accelerated computing with the NVIDIA Hopper™ architecture. Hopper securely scales diverse workloads in every data center, from small enterprise to exascale high-performance computing (HPC) and trillion-parameter AI—so brilliant innovators can fulfill their life's work at the fastest pace in human history.
Explore the Technology Breakthroughs
Built with over 80 billion transistors using a cutting edge TSMC 4N process, Hopper features five groundbreaking innovations that fuel the NVIDIA H200 and H100 Tensor Core GPUs and combine to deliver incredible speedups over the prior generation on generative AI training and inference.
Transformer Engine
The NVIDIA Hopper architecture advances Tensor Core technology with the Transformer Engine, designed to accelerate the training of AI models. Hopper Tensor Cores have the capability to apply mixed FP8 and FP16 precisions to dramatically accelerate AI calculations for transformers. Hopper also triples the floating-point operations per second (FLOPS) for TF32, FP64, FP16, and INT8 precisions over the prior generation. Combined with Transformer Engine and fourth-generation NVIDIA® NVLink®, Hopper Tensor Cores power an order-of-magnitude speedup on HPC and AI workloads.
NVLink, NVSwitch, and NVLink Switch System
To move at the speed of business, exascale HPC and trillion-parameter AI models need high-speed, seamless communication between every GPU in a server cluster to accelerate at scale.
Fourth-generation NVLink can scale multi-GPU input and output (IO) with NVIDIA DGX™ and HGX™ servers at 900 gigabytes per second (GB/s) bidirectional per GPU, over 7X the bandwidth of PCIe Gen5.
Third-generation NVIDIA NVSwitch™ supports Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)™ in-network computing, previously only available on Infiniband, and provides a 2X increase in all-reduce throughput within eight H200 or H100 GPU servers compared to the previous-generation A100 Tensor Core GPU systems.
DGX GH200 systems with NVLink Switch System support clusters of up to 256 connected H200s and deliver 57.6 terabytes per second (TB/s) of all-to-all bandwidth.

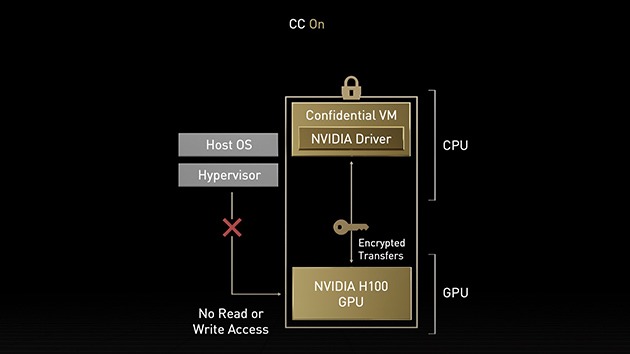
NVIDIA Confidential Computing
While data is encrypted at rest in storage and in transit across the network, it’s unprotected while it’s being processed. NVIDIA Confidential Computing addresses this gap by protecting data and applications in use. The NVIDIA Hopper architecture introduces the world’s first accelerated computing platform with confidential computing capabilities.
With strong hardware-based security, users can run applications on-premises, in the cloud, or at the edge and be confident that unauthorized entities can’t view or modify the application code and data when it’s in use. This protects confidentiality and integrity of data and applications while accessing the unprecedented acceleration of H200 and H100 GPUs for AI training, AI inference, and HPC workloads.
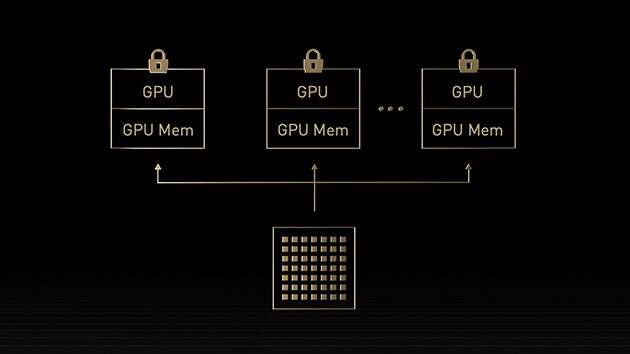
Second-Generation MIG
With Multi-Instance GPU (MIG), a GPU can be partitioned into several smaller, fully isolated instances with their own memory, cache, and compute cores. The Hopper architecture further enhances MIG by supporting multi-tenant, multi-user configurations in virtualized environments across up to seven GPU instances, securely isolating each instance with confidential computing at the hardware and hypervisor level. Dedicated video decoders for each MIG instance deliver secure, high-throughput intelligent video analytics (IVA) on shared infrastructure. And with Hopper’s concurrent MIG profiling, administrators can monitor right-sized GPU acceleration and optimize resource allocation for users.
For researchers with smaller workloads, rather than renting a full CSP instance, they can elect to use MIG to securely isolate a portion of a GPU while being assured that their data is secure at rest, in transit, and at compute.

DPX Instructions
Dynamic programming is an algorithmic technique for solving a complex recursive problem by breaking it down into simpler subproblems. By storing the results of subproblems so that you don’t have to recompute them later, it reduces the time and complexity of exponential problem solving. Dynamic programming is commonly used in a broad range of use cases. For example, Floyd-Warshall is a route optimization algorithm that can be used to map the shortest routes for shipping and delivery fleets. The Smith-Waterman algorithm is used for DNA sequence alignment and protein folding applications.
Hopper’s DPX instructions accelerate dynamic programming algorithms by 40X compared to traditional dual-socket CPU-only servers and by 7X compared to NVIDIA Ampere architecture GPUs. This leads to dramatically faster times in disease diagnosis, routing optimizations, and even graph analytics.