
 MacBook
MacBook iPad
iPad Apple Watch
Apple Watch Airpods
Airpods iMac
iMac Studio Display
Studio Display iphone
iphone
 Gaming Laptop
Gaming Laptop

 Gaming Desktop
Gaming Desktop
 DDR5 Desktop
DDR5 Desktop DDR5 Laptop
DDR5 Laptop DDR5 Server
DDR5 Server DDR4 Desktop
DDR4 Desktop DDR4 Laptop
DDR4 Laptop DDR4 Server
DDR4 Server DDR3 Desktop
DDR3 Desktop DDR3 Laptop
DDR3 Laptop DDR3 Server
DDR3 Server
 Intel Socket
Intel Socket Intel Z890
Intel Z890 Intel B860
Intel B860 Intel B760
Intel B760 Intel H770
Intel H770 Intel B660
Intel B660 Intel H670
Intel H670 Intel H610
Intel H610 Intel Z690
Intel Z690 Intel H510
Intel H510 Intel Z590
Intel Z590 Intel B560
Intel B560 Intel H470
Intel H470 Intel Z490
Intel Z490 Intel H410
Intel H410 Intel B460
Intel B460 Intel H310
Intel H310 Intel B360
Intel B360 Intel B365
Intel B365 Intel X299
Intel X299 Intel Z390
Intel Z390 Intel Z370
Intel Z370 Intel H370
Intel H370 Intel Z270 H270
Intel Z270 H270 Intel B250
Intel B250 Intel Z170 H170
Intel Z170 H170 Intel H110
Intel H110 Intel H81
Intel H81 Intel B85
Intel B85 Intel H61
Intel H61 Intel B150
Intel B150 AMD Socket
AMD Socket AMD B850
AMD B850 AMD B840
AMD B840 AMD TRX50
AMD TRX50 AMD A620
AMD A620 AMD X870
AMD X870 AMD B650
AMD B650 AMD A520
AMD A520 AMD TRX40
AMD TRX40 AMD B550
AMD B550 AMD X570
AMD X570 AMD X470
AMD X470 AMD B450
AMD B450 AMD X370
AMD X370 AMD A320
AMD A320 AMD B350
AMD B350 AMD X399
AMD X399 AMD A88
AMD A88 AMD A68 A78
AMD A68 A78
 Cpu Air Coolers
Cpu Air Coolers CPU Liquid Coolers
CPU Liquid Coolers Fans
Fans
 AMD CPUs Desktop
AMD CPUs Desktop AMD Server CPU
AMD Server CPU Intel Server CPU
Intel Server CPU Samsung CPUs
Samsung CPUs Other special CPUs
Other special CPUs

 Solid State Drives
Solid State Drives NVMe PCIe M.2
NVMe PCIe M.2 SATA 2.5inch
SATA 2.5inch Hard Disk Drive
Hard Disk Drive Server Hard Drives
Server Hard Drives NAS hard drive
NAS hard drive Monitoring hard drive
Monitoring hard drive Portable Solid State Drives
Portable Solid State Drives Memory Cards
Memory Cards USB Flash Drives
USB Flash Drives
 Nvidia GPU
Nvidia GPU RTX 50 series
RTX 50 series RTX 30 series
RTX 30 series GTX 16 series
GTX 16 series GTX 10 series
GTX 10 series RX 9000 series
RX 9000 series RX 7000 series
RX 7000 series RX 6000 series
RX 6000 series RX 5000 series
RX 5000 series RX 500 series
RX 500 series RTX 20 series
RTX 20 series
 Rack server
Rack server Blade server
Blade server Tower server
Tower server Storage Server Solutions
Storage Server Solutions Network switch
Network switch
 Workstation
Workstation Mobile Workstation
Mobile Workstation
 Server motherboard
Server motherboard Workstation Motherboard
Workstation Motherboard
PSP3000索尼原装街机掌机-150x150.jpg) SONY Gaming Console
SONY Gaming Console ASUS Gaming Console
ASUS Gaming ConsoleLegion-Go-游戏掌机手持设备-150x150.jpg) Lenovo Gaming Console
Lenovo Gaming Console One XPlayer
One XPlayer日版-Xbox-Series-X-XSX次世代-150x150.jpg) Microsoft Gaming Console
Microsoft Gaming Console XBOX Gaming Console
XBOX Gaming ConsoleMSI-Claw-A1M-050US-游戏掌机-150x150.jpg) MSI Gaming Console
MSI Gaming Console Motherboard
Motherboard GTX TITAN
GTX TITAN Computer Cases
Computer Cases



Blackwell Architecture
The NVIDIA Blackwell architecture delivers groundbreaking advancements in accelerated computing, powering a new era of computing with unparalleled performance, efficiency, and scale.

NVIDIA Grace CPU
The NVIDIA Grace CPU is a breakthrough processor designed for modern data centers running AI, cloud, and high-performance computing (HPC) applications. It provides outstanding performance and memory bandwidth with 2X the energy efficiency of today’s leading server processors.

NVLINK C2C
NVIDIA NVLink-C2C coherently interconnects each Grace CPU and Blackwell GPU at 900GB/s. The GB200 NVL2 uses both NVLink-C2C and the fifth-generation NVLink to deliver a 1.4 TB coherent memory model for accelerated AI.
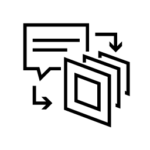
Key Value (KV) Caching
Key Value (KV) Caching improves LLM response speeds by storing conversation context and history. GB200 NVL2 optimizes KV Caching through its fully coherent Grace GPU and Blackwell GPU memory connected by NVLink-C2C, 7X faster than PCIe, enabling LLMs to predict words faster than x86-based GPU implementations.

Fifth-Generation NVIDIA NVLink
Unlocking the full potential of exascale computing and trillion-parameter AI models requires swift, seamless communication between every GPU in a server cluster. Fifth-generation NVLink is a scale-up interconnect that unleashes accelerated performance for trillion- and multi-trillion-parameter AI models.

NVIDIA Networking
The data center’s network plays a crucial role in driving AI advancements and performance, serving as the backbone for distributed AI model training and generative AI performance. NVIDIA Quantum-X800 InfiniBand, NVIDIA Spectrum™-X800 Ethernet, and NVIDIA BlueField®-3 DPUs enable efficient scalability across hundreds and thousands of Blackwell GPUs for optimal application performance.

NVIDIA GB200 NVL72
The NVIDIA GB200 NVL72 connects 36 GB200 Superchips in a rack-scale design. The GB200 NVL72 is a liquid-cooled, rack-scale solution that boasts a 72-GPU NVLink domain that acts as a single, massive GPU.